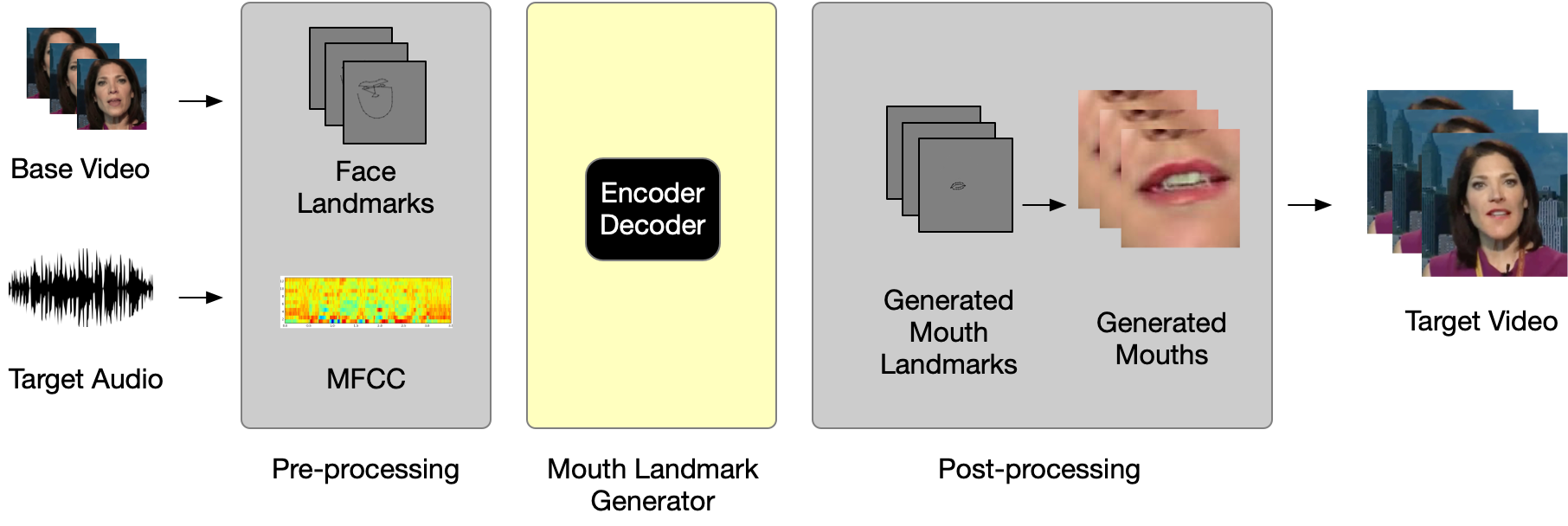
We tackle the problem of generative video dubbing by modifying a video of a person speaking in one language so that the person is perceived as speaking the same content in another language.
The goal of the project is to transform a video of a person speaking in one language so that it looks like the person is speaking the same content in another language. Given a video clip of a person reading a news article in language A, our model produces a video clip of the same person reading the same news article however in language B.
In the media domain, a robust solution to this problem ensures:
- Fast, real-time translation of video broadcast content
- Detection of maliciously altered video content
Altough this task is generative in nature, we propose a novel solution that is different from traditional Generative Adversarial Networks (GANs). Notice that the core of this problem is to generate a series of mouth movements that is conditioned on the audio input – generating RGB pixels is not a crucial part of this task. Thus, we re-formulate this image generation problem into a regression problem by converting RGB facial images to face landmark coordinates using the Dlib face recognition library. It becomes much more computatinally efficient to generate mouth coordinates than pixel values. Then landmark-to-face generation process is outsourced to the Vid2Vid model